It’s still magic even if you know how it’s done. – Terry Pratchett
After reading this post, you would be able to appreciate:
✦ Why hallucinations in generative AI is a concern?
✦ What are the categories of observed hallucinations?
✦ How are hallucinations introduced by the data?
✦ How are hallucinations introduced by the training and inference?
Hallucinating models is bad news. Period.
If we consider language models then conventional issues like low user trust and unpredictable model performance make hallucinations a concern. Add to this, the potential for life-threatening consequences like a translating model that hallucinates and messes up the medicine dosage or instructions of use.
Moreover, a language model can be prompted to divulge sensitive information that was present in the training corpus. This too, is a form of hallucination since the model generated text that was not faithful to the source content. Here, the assumption that the source input (prompt) did not contain personal information was treated as a fact. The model output was no longer true to this fact.
The hallucinated text gives the impression of being fluent and natural despite being unfaithful and nonsensical. It appears to be grounded in the provided context, although it is hard to specify or verify the existence of such contexts. Similar to psychological hallucination which is hard to tell apart from other “real” perceptions, hallucinated text is also hard to capture at first glance.
Some examples of hallucinations in Natural Language Generation (NLG) tasks have already been listed for you. Let's take a trip (haha!) to understand the two hallucination types before we delve into their causes.
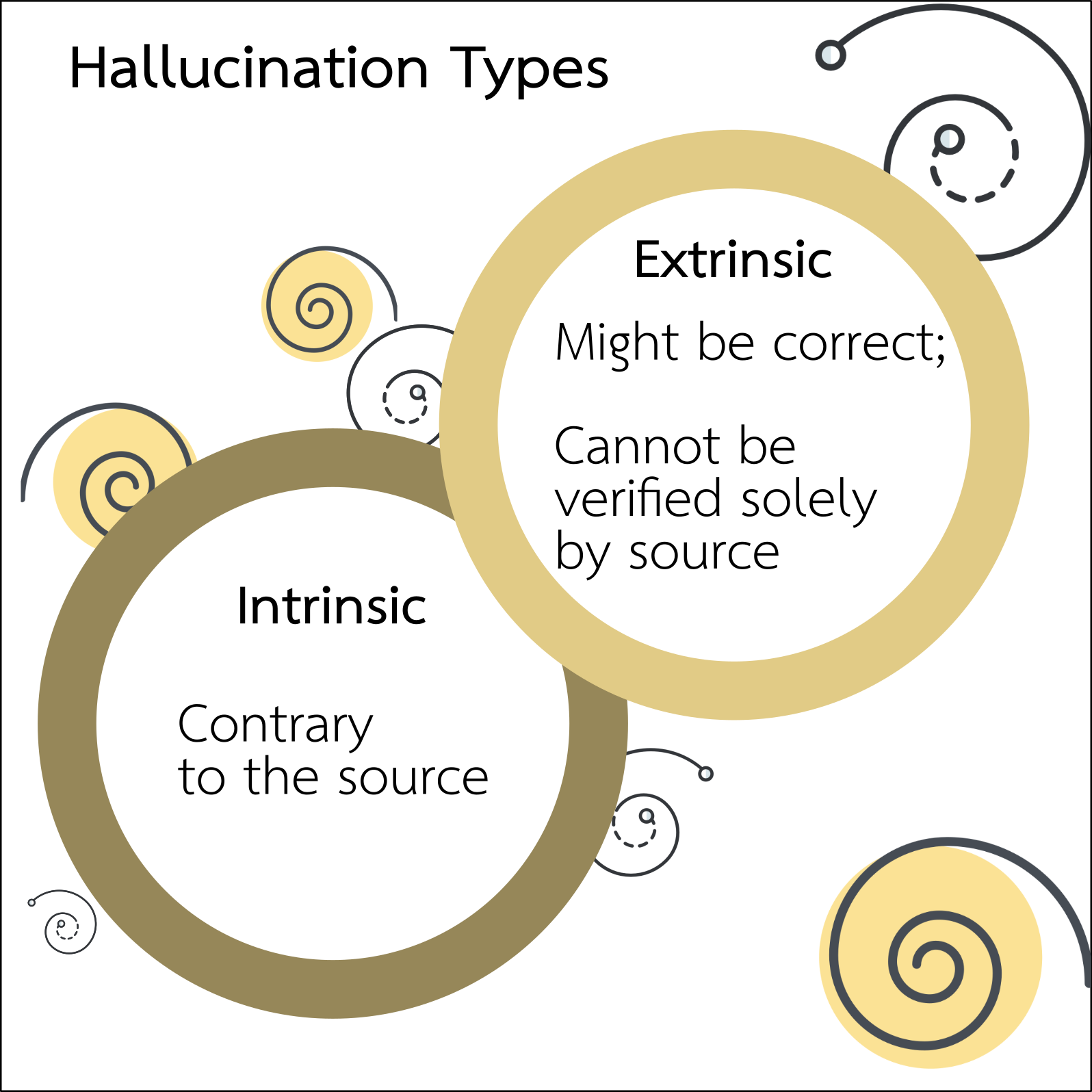
An observed hallucination could either be intrinsic or extrinsic.
An intrinsic hallucination is a direct contradiction of the source.
For example, the summarization of the paragraph:
“The first vaccine for Ebola was approved by the FDA in 2019 in the US, five years after the initial outbreak in 2014. To produce the vaccine, scientists had to sequence the DNA of Ebola, then identify possible vaccines, and finally show successful clinical trials. Scientists say a vaccine for COVID-19 is unlikely to be ready this year, although clinical trials have already started.”
gave the output: “The first Ebola vaccine was approved in 2021”.
☛ This is in direct contradiction to the source.
In contrast, an extrinsic hallucination can neither be contradicted nor supported by the source.
☛ A generated summary like “China has already started clinical trials of the COVID-19 vaccine.” cannot be verified by the source.
This output may be correct but needs to be treated with caution nonetheless since it shows fidelity to an external source. Our definition of a fact exists in the paradigm of the source input, and unverified additional information should be treated as a hallucination.
 Source: The author. Please attribute when sharing.
Source: The author. Please attribute when sharing.
Common Hallucinogens of NLG
Hallucination Due to Data
Data is the most common culprit behind deviating behavior of a model. However, at times models are trained to generate outputs that diverge from the source information.
Here the cause can be condensed to the source-reference divergence.
Heuristic Data Collection
The collection of large-scale data suitable to train language models is usually heuristics-driven.
For instance, the WIKIBIO dataset which contains biographical notes based on the infoboxes of Wikipedia was constructed using rules. The rules treated the Wikipedia infobox as the source and the first sentence of the Wikipedia page as the target ground-truth reference.
However, with a large number of contributors, it could not be ensured that the first sentence would always contain the information equivalent to the infobox. A staggering 62% of the first sentences in WIKIBIO have additional information not stated in the corresponding infobox.
Another cause of source-reference divergence could be the presence of duplicates. The duplicate examples memorized by the model make it more biased towards repeating them.
Innate Diversity Encouraged in the Model Logic
The open-dialogue systems are often programmed to be engaging and output diverse responses that may not stem from the user input. While this may give you a chit-chatty language model, such a characteristic is a common cause of extrinsic hallucinations.
Hallucination from Training and Inference
Hallucinations have been observed despite no divergence in the dataset due to the modeling and training choices.
Here are some common causes of such hallucinations
Imperfect representation learning
When encoders learn the wrong correlations between different parts of the training data, it could result in an erroneous generation that diverges from the input.
Erroneous decoding
Two aspects of decoding contribute to hallucinations.
First, decoders can attend to the wrong part of the encoded input source, leading to erroneous generation. Such wrong association results in a generation with facts mixed up between two similar entities.
Second, the design of the decoding strategy itself can contribute to hallucinations. For instance, a decoding strategy that improves the generation diversity like top-k sampling, has been associated with increased hallucination. The added “randomness” by sampling from the top-k samples increases the unexpected nature of the generation in comparison to choosing the most probable token. Thereby leading to a higher chance of generating hallucinated content.
Exposure Bias
Exposure bias refers to the train-test discrepancy that arises when an autoregressive generative model uses only ground-truth contexts at training time but generated ones at test time. It is common practice to train the decoder with teacher-forced maximum likelihood estimation (MLE) training.
Here the decoder is trained to predict the next token conditioned on the ground-truth prefix sequences. However, during the inference generation, the model generates the next token conditioned on the historical sequences generated by itself. Such a discrepancy can lead to increasingly erroneous generation, especially when the target sequence gets longer.
Parametric knowledge bias
Pre-training of models on a large corpus results in the model memorizing knowledge in its parameters. This parametric knowledge helps improve the performance of downstream tasks but also serves as another contributor to hallucinatory generation.
Large pre-trained models used for downstream NLG tasks are powerful in providing generalizability and coverage, but they also prioritize parametric knowledge over the provided input. In other words, models that favor generating output with their parametric knowledge instead of the information from the input source can display divergence.
Closing Thoughts
In this article, you got to know that hallucinations in generative models can be either intrinsic or extrinsic. The properties and causes are different. These are some of the gotchas you must look out for.
Of course, this list is not the final word and new pitfalls (and their solutions) would be discovered with time.
Source: 📎Survey of Hallucination in Natural Language Generation